Методы повышения эффективности шин 187
использование двухтактных триггеров и/или синхронизация триггеров тактовыми импульсами, что снижает вероятность ошибки до уровня несущественной.
В асинхронных системах имеется иная возможность: специальные схемы для ■обнаружения метастабильных состояний, где асинхронная система вправе просто выждать, пока состояние не станет стабильным.
Методы повышения эффективности шин
Существует несколько приемов, позволяющих повысить производительность шин. К ним, прежде всего, следует отнести пакетный режим, конвейеризацию и расщепление транзакций.
Пакетный режим пересылки информации
Эффективность как выделенных, так и мультиплексируемых шин может быть улучшена, если они функционируют в блочном или пакетном режиме (burst mode), когда один адресный цикл сопровождается множественными циклами данных (чтения или записи, но не чередующимися). Это означает, что пакет данных передается без указания текущего адреса внутри пакета.
При записи в память последовательные элементы блока данных заносятся в последовательные ячейки. Так как в пакетном режиме передается адрес только первой ячейки, все последующие адреса генерируются уже в самой памяти путем последовательного увеличения начального адреса Передача на устройства ввода/ вывода или в память наподобие очереди может не сопровождаться изменением начального адреса.
Скорость передачи собственно данных в пакетном режиме увеличивается естественным образом за счет уменьшения числа передаваемых адресов. Внутри пакета очередные данные могут передаваться в каждом такте шины, длина пакета может достигать 1024 байт. Наиболее частый вариант — пакеты, состоящие из четырех байтов. Такие пакеты используются при работе с памятью в 32-разрядных ВМ, где длина ячейки памяти равна одному байту.
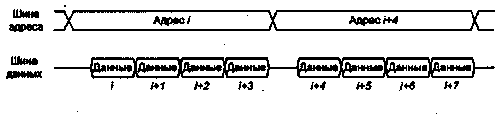
Рис. 4.19. Пакетный режим передачи данных
Рисунок 4.19 иллюстрирует концепцию адресации в пакетном режиме при пересылке данных. По шине адреса передается только адрес ячейки i, а в данных для ячеек i + \,i + 2mi + 3 указание соответствующих адресов отсутствует.
В асинхронных системах пакетный режим позволяет достичь дополнительного эффекта. Как известно, время пересылки слова включает в себя время прохождения слова от отправителя к приемнику и время, затрачиваемое на процедуру подтверждения. Необходимо также учесть внутренние задержки в ведущем-и ведо-