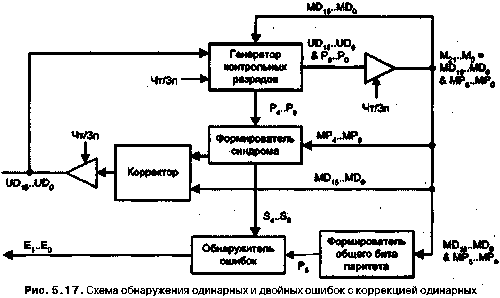
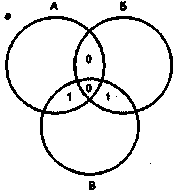Обнаружение и исправление ошибок 2 3 7
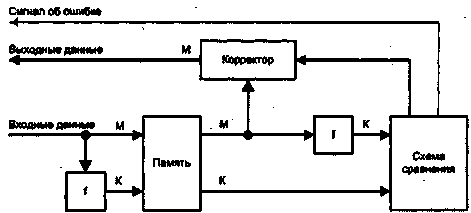
Рис. 5.15 Общая схема обнаружения и исправления ошибок [200]
Коды, используемые для подобных операций, называют корректирующими кодами или кодами с исправлением ошибок.
Простейший вид такого кода основан на добавлении к каждому байту информации одного бита паритета. Бит паритета — это дополнительный бит, значение которого устанавливается таким, чтобы суммарное число единиц в данных, с учетом этого дополнительного разряда, было четным (или нечетным). В ряде систем за основу берется четность, в иных — нечетность. Для 64-разрядного слова требуется восемь битов паритета, то есть ячейка памяти должна хранить 36 разрядов. При записи слова в память для каждого байта формируется бит паритета. Это может быть сделано с помощью схемы в виде дерева, составленного из схем сложения по модулю 2. При чтении из памяти выполняется аналогичная операция над считанными информационными битами, а ее результат сравнивается с битом паритета, вычисленным при записи и хранившимся в памяти. Метод позволяет обнаружить ошибку, если исказилось нечетное количество битов. При четном числе ошибок метод неработоспособен. К сожалению, фиксируя ошибку, данный способ кодирования не может указать на ее местоположение, что позволило бы внести исправления, в силу чего его называют кодом с обнаружением ошибки (ED С — Error Detection Code).
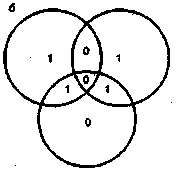
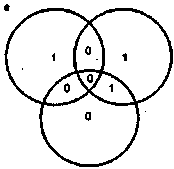
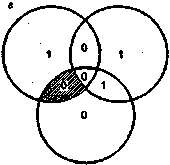
В основе корректирующих кодов лежит достаточно простая идея [39]. Для контроля двоичного информационного кода длиной Мбит добавим к ней Хдополни-тельных контрольных разрядов так, что общая длина последовательности теперь будет равна М + К разрядам. В этом случае из возможных N= Т+к комбинаций интерес представляют только L = Т последовательностей, которые называют разрешенными. Оставшиеся iV- L последовательностей назовем запрещенными. Если при обработке (записи в память, считывании или передаче) разрешенной кодовой последовательности произойдут ошибки и возникнет одна из запрещенных последовательностей, то тем самым эти ошибки обнаруживаются. Если же ошибки превратят одну разрешенную последовательность в другую, то такие ошибки не могут быть обнаружены. Для исправления ошибок необходимо произвести разбиение множества запрещенных последовательностей на L непересекающихся подмно-