24 4 Глава5. Память
Стековая память
Стековая память обеспечивает такой режим работы, когда информация записывается и считывается по принципу «последним записан — первым считан* (LIFO-Last In First Out). Память с подобной организацией широко применяется для запоминания и восстановления содержимого регистров процессора (контекста) при обработке подпрограмм и прерываний. Работу стековой памяти поясняет рис. 5.18, а.
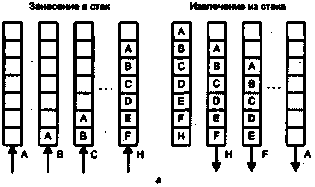
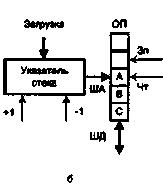
Рис. 5.18. Организация стековой памяти: а — логика работы; б — аппаратно-программный стек
Когда слово А заносится в стек, оно располагается в первой свободной ячейке. Каждое следующее записываемое слово перемещает все содержимое стека на одну ячейку вверх и занимает освободившуюся ячейку. Запись очередного кода, после Н, приводит к переполнению стека и потере кода А. Считывание кодов из стека осуществляется в обратном порядке, то есть начиная с кода Н, который был записан последним. Отметим, что доступ к произвольному коду в стеке формально недопустим до извлечения всех кодов, записанных позже.
Наиболее распространенным в настоящее время является внешний или аппаратно-программный стек, в котором для хранения информации отводится область ОП. Обычно для этих целей отводится участок памяти с наибольшими адресами, а стек расширяется в сторону уменьшения адресов. Поскольку программа обычно загружается, начиная с меньших адресов, такой прием во многих случаях позволяет избежать перекрытия областей программы и стека. Адресация стека обеспечивается специальным регистром — указателем стека (SP — stack pointer), в который предварительно помещается наибольший адрес области основной памяти, отведенной под стек (рис. 5.18, б).
При занесении в стек очередного слова сначала производится уменьшение на единицу содержимого указателя стека (УС), которое затем используется как адрес ячейки, куда и производится запись, то есть указатель стека хранит адрес той ячейки, к которой было произведено последнее обращение. Это можно описать в виде: УС:= УС -1; ОП[(УС)]:=ШД.
При считывании слова из стека в качестве адреса этого слова берется текущее содержимое указателя стека, а после того как слово извлечено, содержимое УС