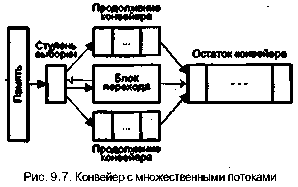
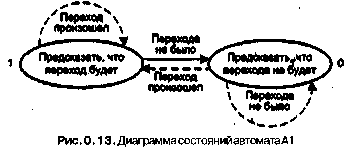
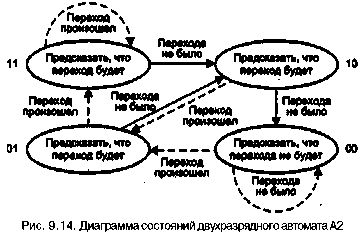
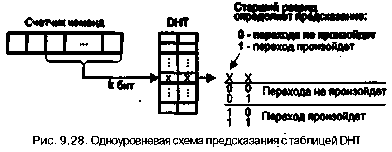
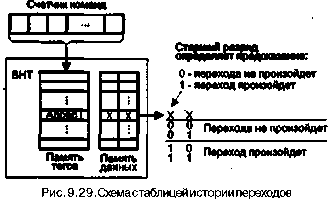
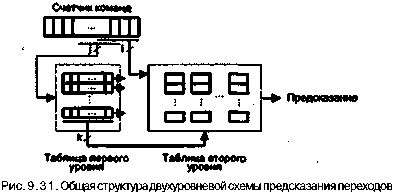
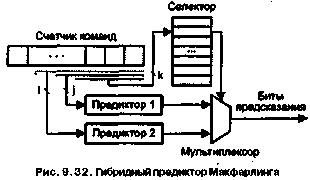
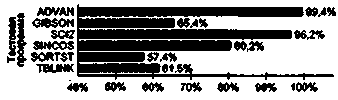42 6 Глава9. Основные направления в архитектуре процессоров
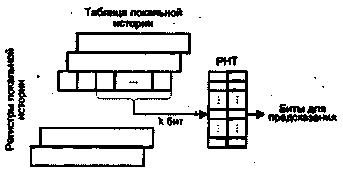
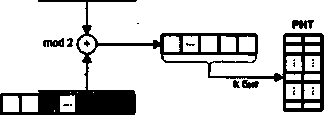
К настоящему моменту известно более двух десятков различных способов реализации идеи предсказания переходов [165,230-232], отличающихся друг от друга исходной информацией, на основании которой делается прогноз, сложностью реализации и, главное, точностью предсказания. При классификации схем предсказания переходов обычно вьщеляют два подхода: статический и динамический, в зависимости от того, когда и на базе какой информации делается предсказание.
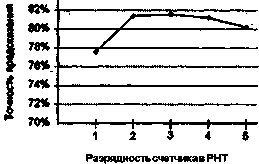
Эффективность большинства из приводимых в учебнике методов предсказания переходов иллюстрируется результатами исследований, опубликованными в [68,95,107,197,207,228]. Все эксперименты проводились по примерно одинаковой методике: численные показатели получены путем имитации методов предсказания переходов при выполнении наборов стандартных тестовых программ. Главное различие заключалось в выборе тестовых программ, что и нашло отражение в существенном расхождении полученных оценок.
Так, в работе Смита [197] использовались шесть тестовых программ, написанных на языке Фортран:
- ADVAN: решение системы из трех дифференциальных уравнений в частных
производных;
- GIBSON: искусственная программа компиляции набора команд, примерно удов-
летворяющего так называемой смеси Гибсона № 5;
- SCI2: обращение матрицы;
- SINCOS: преобразование массива координат из полярной системы отсчета
в прямоугольную;
- SORTST: сортировка массива из 10 000 целых чисел;
- TBLINK: работа со связанным списком.
В прочих исследованиях участвовали программы, входящие в различные версии тестовых пакетов SPEC, в частности пакетов SPEC92, SPEC95 и CPU2000.
Последующий материал раздела посвящен рассмотрению различных механизмов предсказания переходов.
Статическое предсказание переходов
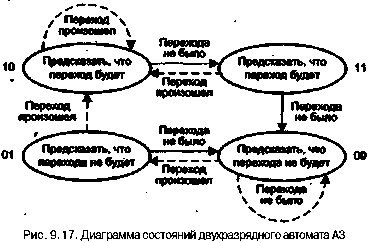
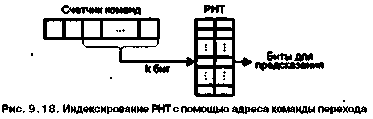
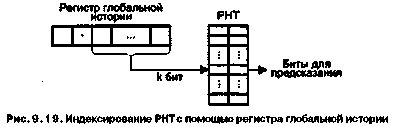
Статическое предсказание переходов осуществляется на основе некоторой априорной информации о подлежащей выполнению программе. Предсказание делается на этапе компиляции программы и в процессе вычислений уже не меняется. Главное различие между известными механизмами статического прогнозирования заключается в виде информации, используемой для предсказания, и ее трактовке. Исходная информация может быть получена двумя путями: на основе анализа кода программы или в результате ее профилирования (термин «профилирование» поясняется ниже).
Известные стратегии статического предсказания для команд УП можно классифицировать следующим образом:
- переход происходит всегда (ПВ);
- переход не происходит никогда (ПН);
- предсказание определяется по результатам профилирования;